
Hi,
W.r.t. Fiasco.OC ...
Can someone give a brief explanation of the Genode PF and IRQ handling architecture. I'd like to understand the path from the kernel to the general or custom handler. My (previous) understanding is that PFs are managed through the core process (which is single threaded running on core0) and farmed off (via signals) to a custom handler if attached. Is there a way to handle a PF without an interaction with 'core'? (assuming let's say I have the memory and the mapping answer).
Likewise with IRQ handling, can someone explain the path from an IRQ firing in the kernel to the app-level handler?
Daniel

Hi Daniel,
Can someone give a brief explanation of the Genode PF and IRQ handling architecture. I'd like to understand the path from the kernel to the general or custom handler. My (previous) understanding is that PFs are managed through the core process (which is single threaded running on core0) and farmed off (via signals) to a custom handler if attached. Is there a way to handle a PF without an interaction with 'core'? (assuming let's say I have the memory and the mapping answer).
the short answer is yes. It is possible to handle page faults without any core interaction. This is how L4Linux works. Here, the Linux kernel directly responds to the page faults raised by the Linux user processes. To install a pager for a given thread, the pager needs to posses a capability selector for the to-be-paged thread. Normally, those selectors never leave core. However, there is a Fiasco.OC-specific extension of the CPU-session interface for obtaining the Fiasco.OC thread capability selector for a given thread. (see 'base-foc/include/foc_cpu_session/').
What would you like to accomplish by paging a thread directly?
I am genuinely interested because in our experience, we found hardly any compelling use case for the handling of on-demand paging by user-level components. There is actually only one service (iso9660) that uses Genode's faciltity for on-demand-paging, namely managed dataspaces. I would like to understand the motivation behind your inquiry.
Likewise with IRQ handling, can someone explain the path from an IRQ firing in the kernel to the app-level handler?
Your question about the general operation of the page-fault handling and IRQ handling calls for a much more elaborative answer.
In general, page faults for all Genode threads outside of core are handled by the pager thread in core. Right now there is a single pager thread on the Fiasco.OC platform. (when using SMP, it would be useful to have one pager thread per CPU) Each time, a thread triggers a page fault, core's pager thread becomes active and performs the following sequence of operations:
1. Based on the page-fault message provided by the kernel, the pager thread determine the identity of the faulting thread (the so-called pager object).
2. Each pager object has an associated RM session, which describes the address-space layout of the process where the thread lives. Several pager objects may share the same RM session (i.e., multiple threads running in the same address space). Once, the RM session is determined, the pager calls the 'Rm_client::pager()' function and passes the fault information as argument.
3. The 'pager' function looks into the RM session to find a valid dataspace at the fault address. If the page fault triggered at an address where a dataspace was attached beforehand (the normal case), a mapping of the dataspace's backing store to the faulter gets established with the reply of the page-fault message. So the page-fault handling works fully synchronously.
Only if the 'pager' function cannot determine a valid mapping, the RM session emits a so-called RM-session fault signal, which may get picked up by a user-level RM-session fault handler. But as I said above, we found that the use cases for such user-level fault handling are actually quite rare. But the ability of handling them is useful anyway (for example to implement automatically growing stacks or detect segmentation faults).
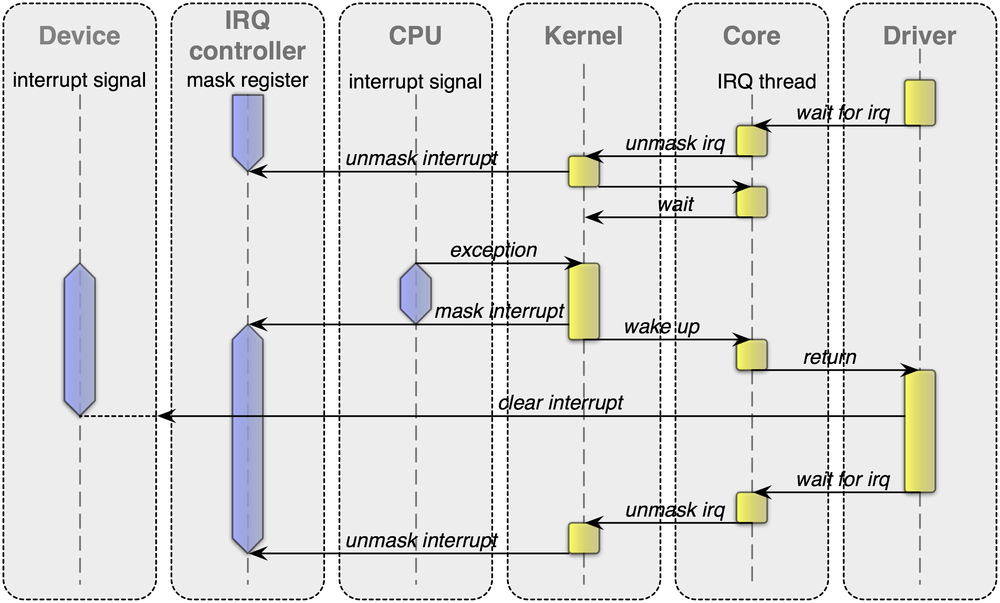
The flow of control when an interrupt occurs is best illustrated by a sequence diagram. The diagram attached to this email depicts the handling of a level-triggered interrupt. It is slightly simpler than the actual implementation (e.g., the handling of shared interrupts is not depicted) but I hope, it helps you to get a general understanding.
Best regards Norman
{kind=link}
Hi Norman,
Basically in perusing the quest for scalability on multicore servers I would like to achieve the following:
1.) Distribute physical memory management across N cores and have each locally handle page faults. The purpose is to eliminate contention on physical memory AVL trees and avoid cross-core IPC as much as possible. Of course this requires partitioning the physical memory space. I also want to avoid eager mapping. 2.) For the purpose of scaling device drivers, I would like to avoid serialization on the IRQ handling. I would like the kernel to deliver the IRQ request message directly to a registered handler or via a 'core' thread on the same core. We then use ACPI to nicely route IRQs across cores and parallelize IRQ handling load - this is useful for multi-queue NICs etc.
I have been exploring the idea of setting up another child of core that has special kernel capabilities (yes I know TCB expansion) so it can set up threads and IRQs in this way. What do you think of this idea?
Can you recommend the best way to achieve goals with Genode (BTW, OmniOS does all this ;-)).
Daniel
-----Original Message----- From: Norman Feske [mailto:norman.feske@...1...] Sent: Wednesday, December 19, 2012 8:59 AM To: genode-main@lists.sourceforge.net Subject: Re: Genode Page-Fault Handling and IRQ architecture
Hi Daniel,
Can someone give a brief explanation of the Genode PF and IRQ handling architecture. I'd like to understand the path from the kernel to the general or custom handler. My (previous) understanding is that PFs are managed through the core process (which is single threaded running on core0) and farmed off (via signals) to a custom handler if attached. Is there a way to handle a PF without an interaction with 'core'? (assuming let's say I have the memory and the mapping answer).
the short answer is yes. It is possible to handle page faults without any
core
interaction. This is how L4Linux works. Here, the Linux kernel directly responds to the page faults raised by the Linux user processes. To install a pager for a given thread, the pager needs to posses a
capability
selector for the to-be-paged thread. Normally, those selectors never leave core. However, there is a Fiasco.OC-specific extension of the CPU-session interface for obtaining the Fiasco.OC thread capability selector for a
given
thread. (see 'base-foc/include/foc_cpu_session/').
What would you like to accomplish by paging a thread directly?
I am genuinely interested because in our experience, we found hardly any compelling use case for the handling of on-demand paging by user-level components. There is actually only one service (iso9660) that uses
Genode's
faciltity for on-demand-paging, namely managed dataspaces. I would like to understand the motivation behind your inquiry.
Likewise with IRQ handling, can someone explain the path from an IRQ firing in the kernel to the app-level handler?
Your question about the general operation of the page-fault handling and IRQ handling calls for a much more elaborative answer.
In general, page faults for all Genode threads outside of core are handled
by
the pager thread in core. Right now there is a single pager thread on the Fiasco.OC platform. (when using SMP, it would be useful to have one pager thread per CPU) Each time, a thread triggers a page fault, core's pager
thread
becomes active and performs the following sequence of operations:
Based on the page-fault message provided by the kernel, the pager thread determine the identity of the faulting thread (the so-called pager object).
Each pager object has an associated RM session, which describes the address-space layout of the process where the thread lives. Several pager objects may share the same RM session (i.e., multiple threads running in the same address space). Once, the RM session is determined, the pager calls the 'Rm_client::pager()' function and passes the fault information as argument.
The 'pager' function looks into the RM session to find a valid dataspace at the fault address. If the page fault triggered at an address where a dataspace was attached beforehand (the normal case), a mapping of the dataspace's backing store to the faulter gets established with the reply of the page-fault message. So the page-fault handling works fully synchronously.
Only if the 'pager' function cannot determine a valid mapping, the RM session emits a so-called RM-session fault signal, which may get picked up
by
a user-level RM-session fault handler. But as I said above, we found that
the
use cases for such user-level fault handling are actually quite rare. But
the
ability of handling them is useful anyway (for example to implement automatically growing stacks or detect segmentation faults).
The flow of control when an interrupt occurs is best illustrated by a
sequence
diagram. The diagram attached to this email depicts the handling of a
level-
triggered interrupt. It is slightly simpler than the actual implementation
(e.g.,
the handling of shared interrupts is not depicted) but I hope, it helps you to get a general understanding.
Best regards Norman
-- Dr.-Ing. Norman Feske Genode Labs
http://www.genode-labs.com · http://genode.org
Genode Labs GmbH · Amtsgericht Dresden · HRB 28424 · Sitz Dresden Geschäftsführer: Dr.-Ing. Norman Feske, Christian Helmuth
Hi Daniel,
thanks for providing more details about the motivation behind your questions. From this information, I gather that you actually do not require the implementation of on-demand-paging policies outside of core. Is this correct?
1.) Distribute physical memory management across N cores and have each locally handle page faults. The purpose is to eliminate contention on physical memory AVL trees and avoid cross-core IPC as much as possible. Of course this requires partitioning the physical memory space. I also want to avoid eager mapping.
I can clearly see how to achieve these goals:
* Genode on Fiasco.OC already populates page tables in a lazy way. There are no eager mappings. When attaching a dataspace to the RM session of a process, the page table of the process remains unchanged. The mapping gets inserted not before the process touches the virtual memory location (and thereby triggers the page-fault mechanism implemented by core).
* To avoid cross-core IPC, there should be one pager thread per core. When setting the affinity of a thread, the pager should be set accordingly. This way, the handling of page faults would never cross CPU boundaries. That is actually quite straight forward to implement. On NOVA, we are even using one pager per thread. The flexibility to do that is built-in into the framework.
Also, I would investigate to use multiple entrypoing (i.e., one for each CPU) to handle core's services. For doing this, we could attach affinity information as session arguments and then direct the session request to the right entrypoint at session-creation time.
* To partition the physical memory, RAM sessions would need to carry affinity information with them - similar to how CPU sessions are already having priority information associated to them. Each RAM session would then use a different pool of physical memory.
2.) For the purpose of scaling device drivers, I would like to avoid serialization on the IRQ handling. I would like the kernel to deliver the IRQ request message directly to a registered handler or via a 'core' thread on the same core. We then use ACPI to nicely route IRQs across cores and parallelize IRQ handling load - this is useful for multi-queue NICs etc.
Maybe the sequence diagram was a bit misleading. It is displaying the sequence for just one IRQ number. For each IRQ, there is a completely different flow of control. I.e., there is one thread per IRQ session in core. The processing of IRQs are not serialized at all. They are processed concurrently.
There are opportunities for optimizations though. For example, we could consider to delegate the capability selectors for the used kernel IRQ objects to the respective IRQ-session clients. This way, we could take core completely out of the loop for the IRQ handling on Fiasco.OC. We haven't implemented this optimization yet for two mundane reasons. First, we wanted to avoid a special case for Fiasco.OC unless we are sure that the optimization is actually beneficial. And second, we handle shared IRQs in core. We haven't yet taken the time for investigating how to handle shared IRQs with the sole use of kernel IRQ objects.
I have been exploring the idea of setting up another child of core that has special kernel capabilities (yes I know TCB expansion) so it can set up threads and IRQs in this way. What do you think of this idea?
To me this looks like you are creating a new OS personality (or runtime) on top of Genode - similar to how L4Linux works. So you are effectively bypassing Genode (and naturally working around potential scalability issues). Personally, I would prefer to improve the underlying framework (in particular the implementation of core) to accommodate your requirements in the first place. This way, all Genode components would benefit, not only those that are children of your runtime.
Cheers Norman
Hi Norman, thanks for your quick reply. Responses inline...
-----Original Message----- From: Norman Feske [mailto:norman.feske@...1...] Sent: Wednesday, December 19, 2012 11:08 AM To: genode-main@lists.sourceforge.net Subject: Re: Genode Page-Fault Handling and IRQ architecture
Hi Daniel,
thanks for providing more details about the motivation behind your questions. From this information, I gather that you actually do not
require
the implementation of on-demand-paging policies outside of core. Is this correct?
Yes.
1.) Distribute physical memory management across N cores and have each locally handle page faults. The purpose is to eliminate contention on physical memory AVL trees and avoid cross-core IPC as much as possible. Of course this requires partitioning the physical memory space. I also want to avoid eager mapping.
I can clearly see how to achieve these goals:
Good. That's encouraging!
Genode on Fiasco.OC already populates page tables in a lazy way. There are no eager mappings. When attaching a dataspace to the RM session of a process, the page table of the process remains unchanged. The mapping gets inserted not before the process touches the virtual memory location (and thereby triggers the page-fault mechanism implemented by core).
To avoid cross-core IPC, there should be one pager thread per core. When setting the affinity of a thread, the pager should be set accordingly. This way, the handling of page faults would never cross CPU boundaries. That is actually quite straight forward to implement. On NOVA, we are even using one pager per thread. The flexibility to do that is built-in into the framework.
Also, I would investigate to use multiple entrypoing (i.e., one for each CPU) to handle core's services. For doing this, we could attach affinity information as session arguments and then direct the session request to the right entrypoint at session-creation time.
Sounds sensible. I would use a mask to future proof for other schedulers.
- To partition the physical memory, RAM sessions would need to carry affinity information with them - similar to how CPU sessions are already having priority information associated to them. Each RAM session would then use a different pool of physical memory.
Could I not use nested RM sessions/dataspaces to help with this?
2.) For the purpose of scaling device drivers, I would like to avoid serialization on the IRQ handling. I would like the kernel to deliver the IRQ request message directly to a registered handler or via a 'core' thread on the same core. We then use ACPI to nicely route IRQs across cores and parallelize IRQ handling load - this is useful for
multi-queue
NICs etc.
Maybe the sequence diagram was a bit misleading. It is displaying the sequence for just one IRQ number. For each IRQ, there is a completely different flow of control. I.e., there is one thread per IRQ session in
core. The
processing of IRQs are not serialized at all. They are processed
concurrently.
There are opportunities for optimizations though. For example, we could consider to delegate the capability selectors for the used kernel IRQ
objects
to the respective IRQ-session clients. This way, we could take core completely out of the loop for the IRQ handling on Fiasco.OC. We haven't implemented this optimization yet for two mundane reasons. First, we wanted to avoid a special case for Fiasco.OC unless we are sure
that
the optimization is actually beneficial. And second, we handle shared IRQs
in
core. We haven't yet taken the time for investigating how to handle shared IRQs with the sole use of kernel IRQ objects.
I have been exploring the idea of setting up another child of core that has special kernel capabilities (yes I know TCB expansion) so it can set up threads and IRQs in this way. What do you think of this
idea?
To me this looks like you are creating a new OS personality (or runtime)
on
top of Genode - similar to how L4Linux works. So you are effectively bypassing Genode (and naturally working around potential scalability
issues).
Personally, I would prefer to improve the underlying framework (in
particular
the implementation of core) to accommodate your requirements in the first place. This way, all Genode components would benefit, not only those that are children of your runtime.
Yes, I guess so - that is providing it makes sense for the general Genode distribution. Also, this might be a stop-gap until we/you get some of the changes into Genode.
Daniel
Hi Daniel,
- To partition the physical memory, RAM sessions would need to carry affinity information with them - similar to how CPU sessions are already having priority information associated to them. Each RAM session would then use a different pool of physical memory.
Could I not use nested RM sessions/dataspaces to help with this?
I am not 100% convinced that nested RM sessions would be the best way to go because you just want to tailor the allocation strategy of physical memory. Whereas the on-demand paging facility of nested RM sessions will remain unused, the overhead must be paid. But the general idea to virtualize core's RAM session on top of core points into the right direction. (similar to how the ACPI driver virtualizes core's IRQ service to support IRQ remapping)
Maybe the sequence diagram was a bit misleading. It is displaying the sequence for just one IRQ number. For each IRQ, there is a completely different flow of control. I.e., there is one thread per IRQ session in
core. The
processing of IRQs are not serialized at all. They are processed
concurrently.
After checking back with Sebastian about this, I learned that currently, base-foc does indeed have one central thread that dispatches IRQs coming from the kernel to the various IRQ threads within core. Even though this dispatcher thread is active for a brief period of time only, IRQs are first delivered to always the same CPU, which you like to avoid. Therefore, we should employ one thread per CPU or go for the optimizations I outlined in my last email.
Yes, I guess so - that is providing it makes sense for the general Genode distribution. Also, this might be a stop-gap until we/you get some of the changes into Genode.
That sounds good to me.
Cheers Norman
BTW, I think a really good use of the on-demand nested paging is to support distributed shared memory. We did implemented on Genode a basic shared memory solution back in 2010.
Daniel
-
 Daniel Waddington
Daniel Waddington -
 Norman Feske
Norman Feske