
Hi Daniel,
Can someone give a brief explanation of the Genode PF and IRQ handling architecture. I'd like to understand the path from the kernel to the general or custom handler. My (previous) understanding is that PFs are managed through the core process (which is single threaded running on core0) and farmed off (via signals) to a custom handler if attached. Is there a way to handle a PF without an interaction with 'core'? (assuming let's say I have the memory and the mapping answer).
the short answer is yes. It is possible to handle page faults without any core interaction. This is how L4Linux works. Here, the Linux kernel directly responds to the page faults raised by the Linux user processes. To install a pager for a given thread, the pager needs to posses a capability selector for the to-be-paged thread. Normally, those selectors never leave core. However, there is a Fiasco.OC-specific extension of the CPU-session interface for obtaining the Fiasco.OC thread capability selector for a given thread. (see 'base-foc/include/foc_cpu_session/').
What would you like to accomplish by paging a thread directly?
I am genuinely interested because in our experience, we found hardly any compelling use case for the handling of on-demand paging by user-level components. There is actually only one service (iso9660) that uses Genode's faciltity for on-demand-paging, namely managed dataspaces. I would like to understand the motivation behind your inquiry.
Likewise with IRQ handling, can someone explain the path from an IRQ firing in the kernel to the app-level handler?
Your question about the general operation of the page-fault handling and IRQ handling calls for a much more elaborative answer.
In general, page faults for all Genode threads outside of core are handled by the pager thread in core. Right now there is a single pager thread on the Fiasco.OC platform. (when using SMP, it would be useful to have one pager thread per CPU) Each time, a thread triggers a page fault, core's pager thread becomes active and performs the following sequence of operations:
1. Based on the page-fault message provided by the kernel, the pager thread determine the identity of the faulting thread (the so-called pager object).
2. Each pager object has an associated RM session, which describes the address-space layout of the process where the thread lives. Several pager objects may share the same RM session (i.e., multiple threads running in the same address space). Once, the RM session is determined, the pager calls the 'Rm_client::pager()' function and passes the fault information as argument.
3. The 'pager' function looks into the RM session to find a valid dataspace at the fault address. If the page fault triggered at an address where a dataspace was attached beforehand (the normal case), a mapping of the dataspace's backing store to the faulter gets established with the reply of the page-fault message. So the page-fault handling works fully synchronously.
Only if the 'pager' function cannot determine a valid mapping, the RM session emits a so-called RM-session fault signal, which may get picked up by a user-level RM-session fault handler. But as I said above, we found that the use cases for such user-level fault handling are actually quite rare. But the ability of handling them is useful anyway (for example to implement automatically growing stacks or detect segmentation faults).
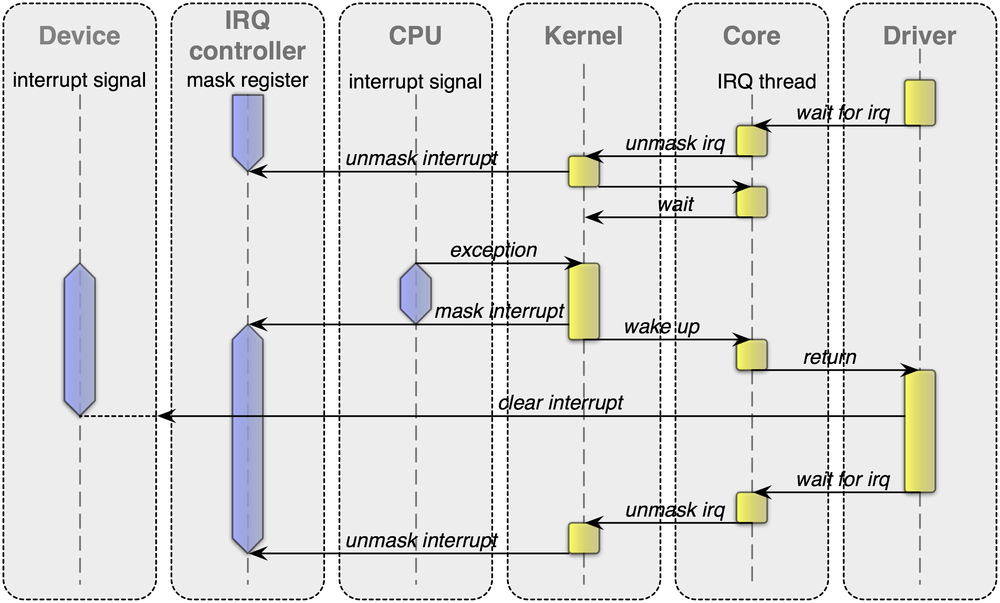
The flow of control when an interrupt occurs is best illustrated by a sequence diagram. The diagram attached to this email depicts the handling of a level-triggered interrupt. It is slightly simpler than the actual implementation (e.g., the handling of shared interrupts is not depicted) but I hope, it helps you to get a general understanding.
Best regards Norman
{kind=link}